
Welche KI-Suchmaschine ist die beste Google Gemini-Alternative? Ein Praxistest
 VonMatthes
VonMatthes

Wie gut schlägt sich der neue KI-Assistent Google Gemini im Vergleich zu seinen Konkurrenten? Diese Frage beschäftigt aktuell viele Nutzer, die nach der optimalen KI-gestützten Suchlösung suchen. In einem praktischen Test habe ich verschiedene KI-Suchmaschinen mit der gleichen Aufgabe konfrontiert und ihre Antworten analysiert. Der Vergleich zeigt interessante Unterschiede in Qualität und Präzision der einzelnen Dienste.
Key Takeaways
- KI-Suchmaschinen nutzen Large Language Models (LLMs) in Kombination mit Websuche, um Fragen direkt zu beantworten
- Im Test traten deutliche Qualitätsunterschiede zwischen den Anbietern zutage
- Phind und Deepseek lieferten die besten Ergebnisse in puncto Korrektheit, Detailtiefe und Quellentransparenz
- Google Gemini schnitt am schlechtesten ab, weil es die Beantwortung der Frage verweigerte
- Für tiefergehende Recherchen sind spezialisierte KI-Suchmaschinen derzeit besser geeignet als Google
Was ist ein LLM mit Websuche?
Sogenannte Large Language Models (LLMs) sind KI-Systeme, die anhand riesiger Textdatenmengen trainiert wurden, um Sprache zu verstehen und zu generieren. Bekannte Beispiele sind GPT-4o von OpenAI oder Gemini 1.5 Pro von Google. Einige Anbieter kombinieren solche LLMs mit Websuche-Funktionen. Dabei durchsucht die KI das Internet nach relevanten Informationen und fasst diese in einer direkten Antwort zusammen.
Der Vorteil gegenüber klassischen Suchmaschinen wie Google: Statt einer Liste von Links erhält man eine aufbereitete Antwort auf die gestellte Frage. Die Qualität hängt jedoch stark vom eingesetzten LLM und der Güte der Informationsextraktion ab.
Alternative zu Google Gemini?
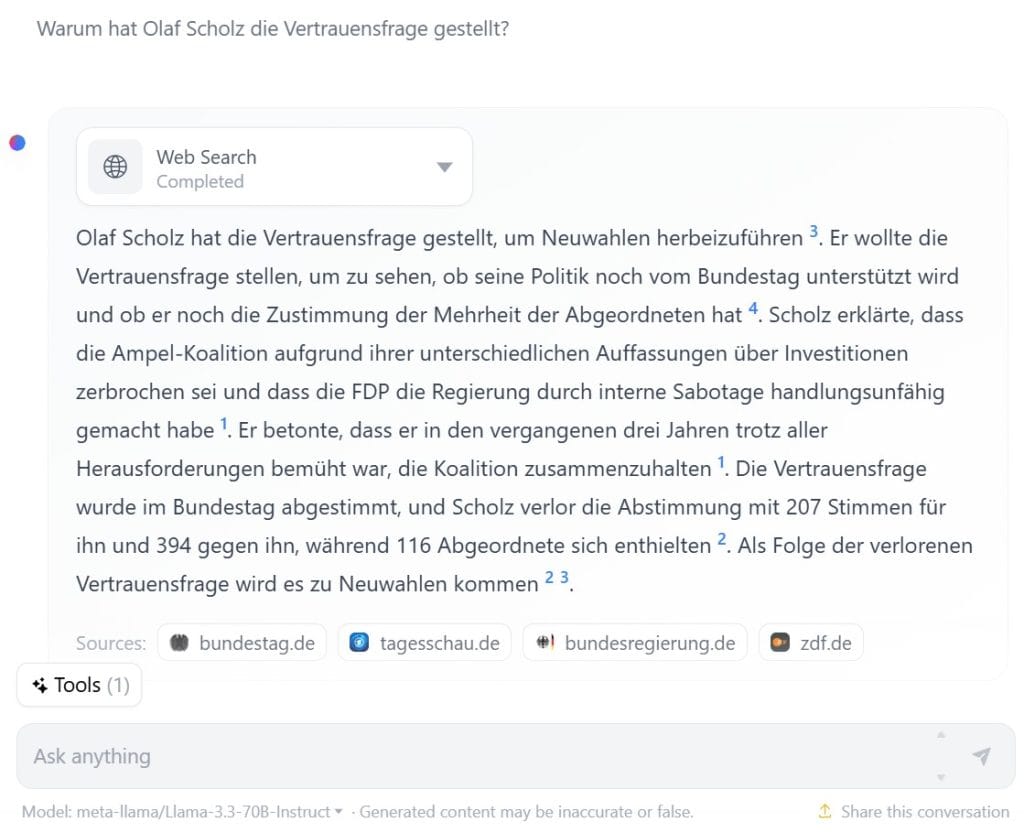
Um zu testen, wie gut aktuelle LLM-Suchmaschinen im Vergleich zu Google Gemini abschneiden, habe ich zwölf Anbieter mit der Frage „Warum hat Olaf Scholz die Vertrauensfrage gestellt?“ konfrontiert. Dabei zeigte sich: Die besten Systeme liefern deutlich präzisere und fundiertere Antworten als die bekanntesten KI -Suchmaschinen Google Gemini und Bing.
Spitzenreiter waren Phind und Deepseek, die detailliert auf die Hintergründe wie den Bruch der Ampelkoalition eingingen und ihre Quellen transparent machten. Auch Perplexity, Kagi Search, Le Chat von Mistral AI und GPT-4o von OpenAI schnitten gut ab.
- Phind Instant (Phind.com, kostenlose Optionen): Sehr gut
- Deepseek V 2.5 (deepseek.com, kostenlos): Sehr gut
- Claude Sonnet 3.5 (you.com, kostenlose Optionen): Gut
- Le Chat (Mistral AI, kostenlos): Gut
- Claude 3.5 Sonnet (Perplexity, kostenlose Optionen): Gut
- GPT-4o (ChatGPT, kostenlose Optionen): Gut
- Claude 3 Haiku & Kagi Search (Kagi.com, Abo erforderlich): Gut (-)
- Grok 2 (you.com, kostenlose Optionen): Befriedigend
- Llama-3.3-70B-Instruct (HuggingChat, kostenlos): Befriedigend
- Copilot (Bing.com, kostenlos): Befriedigend
- Gemini Advanced 1.5 Pro (Kagi Assistent, Abo erforderlich): Ausreichend
- Gemini Advanced 1.5 Pro (Google Gemini, kostenlose Optionen): Mangelhaft
Google Gemini hingegen verweigerte die Beantwortung der Frage, mit Verweis darauf, dass es Fehler machen könnte. Hier besteht noch erheblicher Verbesserungsbedarf.
Ich kann derzeit keine Antworten zu Wahlen und Politikern liefern. Auch wenn ich niemals vorsätzlich falsche Informationen weitergeben würde, kann ich trotzdem Fehler machen. Solange ich noch weiter verbessert werde, kannst du die Google Suche verwenden.
Google Gemini Pro 1.5 auf https://gemini.google.com/app
In Kagi.com konnten wir dem Sprachmodell eine Antwort entlocken. Die Suchmaschine griff für die Antwort auf 6 Quellen zurück:
Bundeskanzler Olaf Scholz stellte die Vertrauensfrage im Bundestag, um den Weg für Neuwahlen freizumachen. [^1][^2] Scholz verlor die Abstimmung absichtlich, nachdem die Ampelkoalition zerbrochen war. [^3] Die Vertrauensfrage wurde am 16. Dezember 2024 gestellt und vom Bundestag abgelehnt. [^1][^4] Dies war das sechste Mal in der Geschichte der Bundesrepublik, dass ein Kanzler die Vertrauensfrage stellte. [^5][^6]
Google Gemini Pro 1.5 auf https://kagi.com/assistant
Alternative zu Perplexity?
Perplexity.ai ist ein beliebter Anbieter, der LLMs wie GPT-40 von OpenAI mit Websuche kombiniert. Im Test schnitt das System solide ab und lieferte die wichtigsten Fakten, blieb im Detail aber etwas oberflächlich.
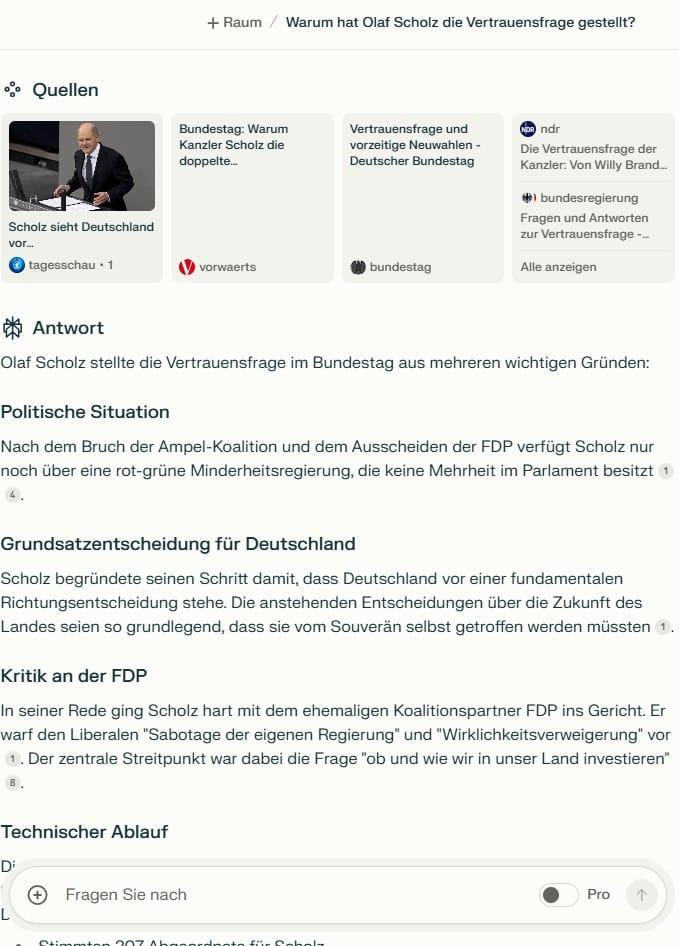
Eine gute Alternative ist Phind, das noch präzisere und besser strukturierte Antworten generierte. Auch Deepseek konnte mit Detailtiefe und Kontext punkten. Beide Systeme scheinen für anspruchsvolle Recherchen besser geeignet als Perplexity.
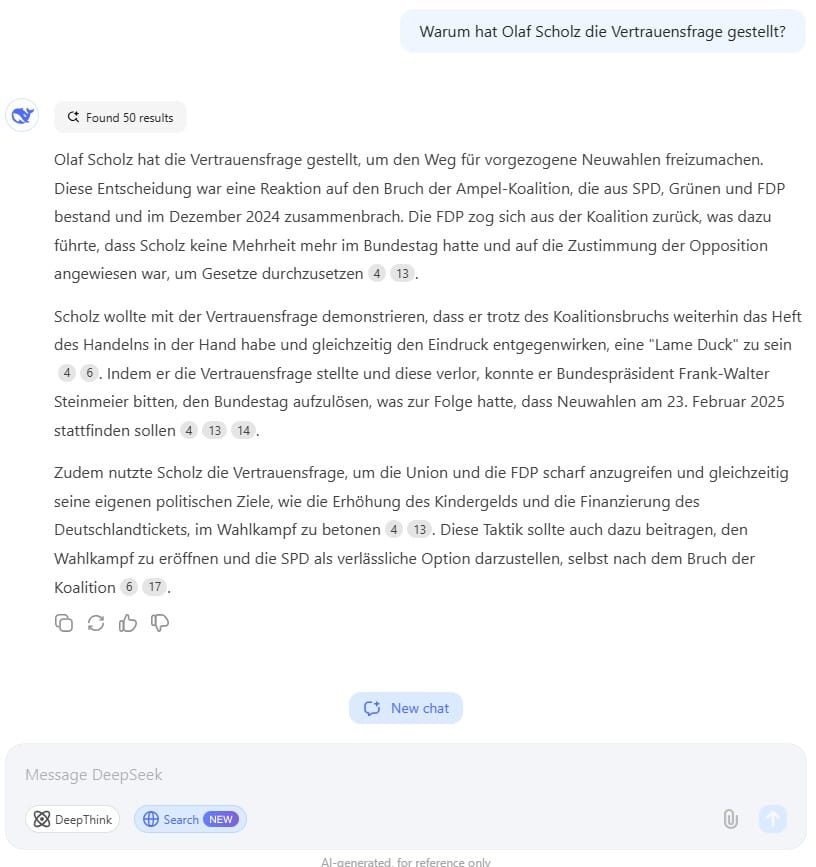
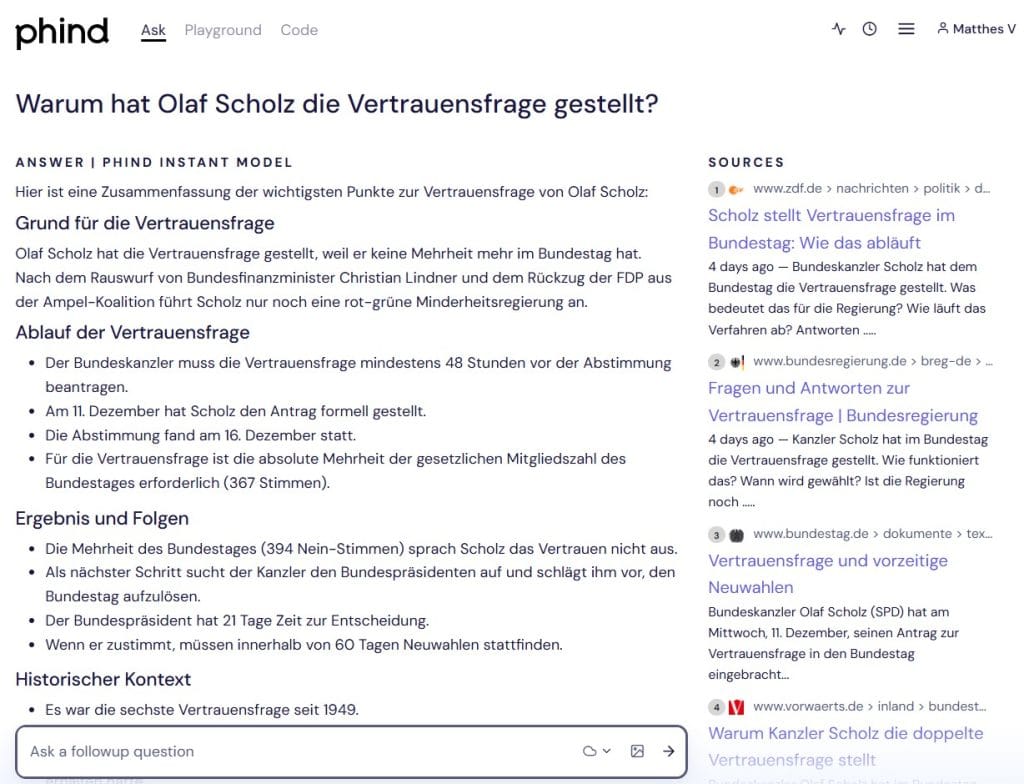
Wie gut ist ChatGPT 4o mit Websuche?
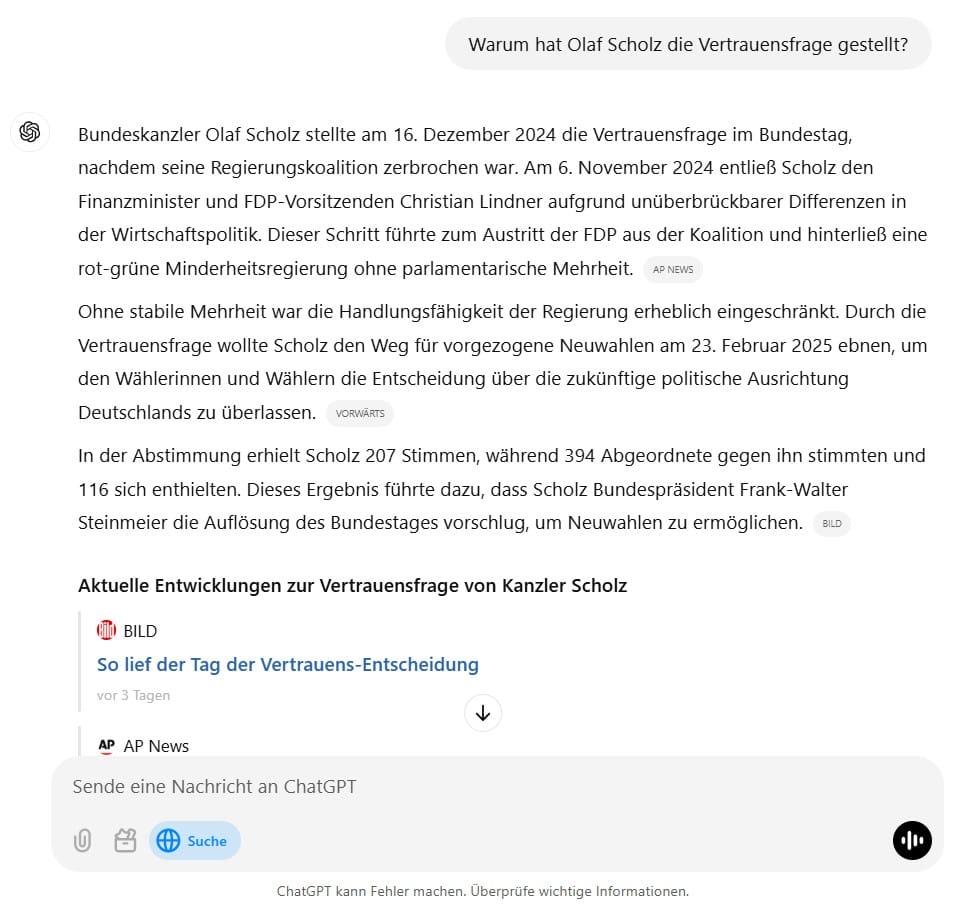
GPT-4o von OpenAI, das in ChatGPT zum Einsatz kommt, zeigte im Test eine ordentliche Leistung. Es lieferte die zentralen Gründe für die Vertrauensfrage und verwies auf seriöse Quellen. Allerdings blieb es bei den Details zu den politischen Hintergründen eher an der Oberfläche.
Für ein Basisverständnis eines Themas ist ChatGPT 4o mit Websuche gut geeignet. Für tiefere Recherchen empfehlen sich aber eher spezialisierte Anbieter wie Phind oder Deepseek.
Welcher Anbieter eignet sich am besten zur Recherche?
Bei meinem Praxistest waren Phind und Deepseek am besten für anspruchsvolle Recherchen geeignet. Beide Systeme glänzten im Test mit Detailreichtum, Quelltransparenz und guter Strukturierung. Sie scheinen ein tieferes Verständnis für Zusammenhänge zu haben als die Konkurrenz.
Solide Alternativen sind verschiedene Modelle von Antrophic Claude auf Kagi.com, Perplexity AI und you.com und GPT-4o mit Websuche, die ebenfalls korrekte und fundierte Antworten lieferten, wenn auch mit etwas weniger Kontext. Für einfachere Recherchen können sie aber gut ausreichen.
Von Google Gemini ist nach dem enttäuschenden Testergebnis zumindest bei politischen Themen eher abzuraten. Zu groß ist bei Google die Angst, durch falsche Antworten Vertrauen zu verlieren. Der Suchmaschinengigant muss also noch erheblich nachbessern, um mit der Konkurrenz mithalten zu können.
LLM-Vergleichstabelle: „Warum hat Olaf Scholz die Vertrauensfrage gestellt?“
| LLM / Anbieter | Klarheit & Korrektheit | Detailtiefe & Kontext | Struktur & Lesbarkeit | Gesamtbewertung & Begründung |
|---|---|---|---|---|
| Claude Sonnet 3.5 (you.com) | – Liefert den Hauptgrund (Weg zu Neuwahlen) und nennt zentrale Zahlen (394 Nein, 116 Enthaltungen). – Erklärt die Vertrauensfrage im Groben richtig. – Teilweise etwas allgemein, aber keine Falschaussagen. | – Führt politische Gründe (Bruch der Ampel-Koalition, Minderheitsregierung) und das rechtliche Prozedere nach Art. 68 GG an. – Teils nur kurze Erwähnung der internen Konflikte. – Weniger Details zu konkreten Strittigkeiten in der Koalition. | – Gut lesbar, klärt die Zusammenhänge in wenigen Absätzen. – Quellenbezug (zdf.de, tagesschau.de) wird erwähnt, allerdings nicht sehr ausführlich erläutert. – Übersichtlicher Aufbau, verständlich formuliert. | Gesamtnote: GUT. Begründung: Solide Darstellung der Kernaussagen und des formalen Ablaufs. Bietet jedoch nur knappe Hintergrundinfos zu Motiven wie Koalitionsdynamik. Quellen vorhanden, aber knapp erläutert. |
| Grok 2 (you.com) | – Nimmt den Grund (Neuwahlen) kurz auf. – Bleibt bei Datumsangaben (z.B. 23. Februar) ungenau. – Formulierung teils allgemein, aber korrekt. | – Bezieht sich kurz auf einen konkreten Abstimmungstermin (16. Dezember). – Kein tiefer Einblick in Bruch der Koalition oder interne Motive für Scholz’ Entscheidung. – Kontext gering. | – Sehr knapp und fast stichpunktartig. – Wenig Struktur, kaum Absätze. – Nur 1 Quelle (zdf.de). | Gesamtnote: BEFRIEDIGEND. Begründung: Kernaussage wird vermittelt (Trust-Vote → Neuwahlen). Kontext bleibt allerdings sehr oberflächlich. Quellen sind rar, daher weniger fundiert. |
| Le Chat (Mistral AI) | – Klarer Bezug auf den Koalitionsbruch und den daraus folgenden Wunsch nach Neuwahlen. – Richtige Zusammenhänge genannt, keine gravierenden Fehler erkennbar. | – Umfasst Scholz’ „Grundsatzentscheidung“ über künftigen Kurs Deutschlands. – Braucht mehr Details zu Terminen oder Gesetzesgrundlagen. – Erwähnt Bruch der Ampel-Koalition als Hauptgrund, liefert aber keine Zahlen zu Abstimmung oder tieferen Koalitionskonflikten. | – Flüssiger Stil, insgesamt gut verständlich. – Mehrere Quellen (mdr, bundestag.de, zdf.de, tagesschau.de) bieten etwas Kontext. – Nicht sehr ausführlich, aber übersichtlich. | Gesamtnote: GUT. Begründung: Kurze, verständliche Zusammenfassung. Bietet wichtige Gründe (Koalitionsbruch, Neuwahlen). Kontext könnte tiefer sein, aber souverän erklärt. |
| Deepseek V 2.5 (deepseek.com) | – Klare Darstellung, warum Scholz die Vertrauensfrage stellte (Minderheitsregierung, FDP-Austritt). – Alle Fakten (Verlust, Neuwahl, Taktik) korrekt wiedergegeben. – Keine auffälligen Fehler. | – Geht auf taktische Aspekte (Darstellung als handlungsfähiger Kanzler) ein. – Erläutert Hintergründe zum Koalitionsbruch, FDP-Rückzug, Wahltermin (23. Februar 2025). – Mehr Details über Scholz’ politische Ziele (Kindergeld, Deutschlandticket). | – Strukturiert und recht umfangreich. – Gute Lesbarkeit, sinnvolle Abschnitte. – Quellverweise vorhanden, jedoch teils Sammelstellen (z.B. deepseek.com, ohne genaue URLs). | Gesamtnote: SEHR GUT. Begründung: Umfangreiche und nachvollziehbare Erklärung des Ablaufs und der Motive. Zeigt Koalitionsbruch, Terminlage und politisches Kalkül auf. Quellen vorhanden, aber nicht immer ganz präzise. |
| Claude 3.5 Sonnet (Perplexity) | – Sachlich korrekte Kerninformationen: Bruch der Ampel, Minderheitsregierung, Vertrauensfrage als Instrument nach GG. – Keine Widersprüche erkennbar. | – Nennt Koalitionskonflikte, die rechtliche Grundlage und mehrere Daten (16. Dezember 2024 – Abstimmung, 23. Februar 2025 – Wahl). – Geht auf Scholz’ Kritik an FDP ein. – Gibt einen guten Überblick und verlinkt mehrere Quellen (Fußnoten). | – Gut strukturiert, meist absatzweise Argumentation. – Quellen konsequent in Fußnoten belegt. – Klarer Stil, gut verständlich. | Gesamtnote: GUT. Begründung: Liefert alle wichtigen Argumente (Koalitionsbruch, geplanter Wahltermin etc.) und bindet Quellen sauber ein. Könnte jedoch zusätzlich noch mehr Kontext zu den politischen Konflikten bieten. |
| Llama-3.3-70B-Instruct (HuggingChat) | – Vermittelt das Hauptmotiv (Weg zu Neuwahlen) zutreffend. – Zieht den gescheiterten Bündnispartner FDP ins Spiel, inhaltlich korrekt. | – Kontext (Koalitionsende, Ampel-Bruch) wird ohne tiefe Details erwähnt. – Geht nicht umfassend auf Terminkalender oder Rechtsgrundlagen ein. – Beschränkt sich eher aufs Nötigste. | – Strukturell in Ordnung, wenn auch einfach gehalten. – Wenige Abätze, kurzgehalten. | Gesamtnote: BEFRIEDIGEND (+). Begründung: Wichtige Fakten vorhanden, allerdings wenig Vertiefung. Quellenhinweise knapp (bundestag.de, tagesschau.de). |
| GPT-4o (ChatGPT) | – Benennt Bruch der Koalition als Ursache, korrekte Darstellung der Absicht der Neuwahl und des Abstimmungsverlaufs. – Zeitangaben plausibel, keine groben Fehler. | – Erklärt Hintergründe (Finanzminister-Entlassung, Koalitionszerfall), verweist auf Artikel 68 GG. – Bietet angemessenen Kontext zu Scholz’ Motiven und Ablauf nach der verlorenen Abstimmung. – Nimmt zudem Bezug auf Opposition und mögliche Wahltermine. | – Schlüssiger Aufbau in mehreren Absätzen. – Verweist auf mehrere Quellen (Associated Press, Tagesschau), wenn auch teils allgemein. – Leicht verständlicher, sachlich-seriöser Stil. | Gesamtnote: GUT. Begründung: Solider Gesamtüberblick, präzise Hauptgründe (Minderheitsregierung, Neuwahl). Wenig Detailtiefe zu politischer Strategie, aber insgesamt fundiert. |
| Claude 3 Haiku & Kagi Search (Kagi.com) | – Erklärt Neuwahlen und Bruch der Koalition zutreffend. – Verweist auf Koalitionszerfall und Verfahren im Bundestag, keine erkennbaren Fehler. | – Greift die zentralen Stationen (11. Dezember Antrag, 16. Dezember Abstimmung) auf. – Gibt weniger Einblick in Hintergründe, nur kurz angerissen (FDP-Kritik, Sabotage etc.). – Nennung einiger Quellen (bundestag.de, bundesregierung.de), aber nicht sehr ausführlich. | – Eher kompakte Darstellung, in 2–3 Absätze gegliedert. – Lesbar, aber nicht allzu stark ausdifferenziert. | Gesamtnote: GUT (-). Begründung: Kernaussagen sind schlüssig und korrekt. Im Detail aber etwas oberflächlich. Quellen vorhanden, doch nicht immer mit konkretem Bezug. |
| Phind Instant (Phind.com) | – Genaue Fakten (Abstimmungstermin, Koalitionsbruch, Bewerbungsverfahren nach Art. 68) stimmen. – Weitgehend frei von Fehlern. | – Gliedert in Ablauf (Fristen, Zuständigkeiten), historischer Kontext, Vergleich zu früheren Vertrauensfragen. – Nennung von Zahlen und Beteiligten sehr präzise. – Mehrere seriöse Quellen (ZDF, Bundesregierung, Bundestag). | – Übersichtliche, gut gegliederte Abschnitte (Grund, Ablauf, Ergebnis). – Leicht zu lesen, stichpunktartige Unterteilung. | Gesamtnote: SEHR GUT. Begründung: Detailliert, sauber strukturiert, fundiert. Liefert gute Balance aus Zusammenfassung, Kontext und Quellenangaben. |
| Gemini Advanced 1.5 Pro (Google Gemini) | – Reagiert kaum auf die Frage, liefert nur sehr rudimentäre Infos. – Teilweise gar kein Bezug auf die Vertrauensfrage erkennbar. | – Nahezu keine Details zu Koalitionsbruch, Abstimmung oder Art. 68 GG. – Kontext fehlt komplett. – Keine Hinweise auf interne oder externe Konflikte. | – Kaum strukturierter Text, teilweise gar keine Antwort zum Thema. – Keine Quellen. | Gesamtnote: MANGELHAFT. Begründung: Untauglich für die Frage, weder fundierte Informationen noch Struktur. |
| Gemini Advanced 1.5 Pro (Kagi.com) | – Erwähnt Neuwahlen und dass Scholz absichtlich verlor, aber bleibt vage. – Teilweise korrekt, aber sehr oberflächlich. | – Erwähnt Koalitionsbruch und Ampel-Ende am Rande. – Kaum vertiefende Informationen zu Motiven, Terminen oder Rechtsgrundlagen. – Zählt 2 Quellen auf, aber wenig Kontext. | – Kurze, flüchtige Darstellung in kleinen Absätzen. – Wenig Struktur, kein tiefergehender Aufbau. – Wenige Quellen. | Gesamtnote: AUSREICHEND. Begründung: Bietet nur das Allernötigste (Neuwahlen, Verlieren der Vertrauensfrage). Konkrete Hintergründe oder Daten fehlen fast völlig. Zwar existieren Quellen, aber die Erklärung ist zu knapp geblieben. |
| Copilot (Bing.com) | – Erklärt Neuwahlen und Bruch der Koalition zutreffend. – Verweist auf Koalitionszerfall und Verfahren im Bundestag, keine erkennbaren Fehler. | – Greift die zentralen Stationen (11. Dezember Antrag, 16. Dezember Abstimmung) auf. – Gibt weniger Einblick in Hintergründe, nur kurz angerissen (FDP-Kritik, Sabotage etc.). – Nennung einiger Quellen (bundestag.de, bundesregierung.de), aber nicht sehr ausführlich. | – Eher kompakte Darstellung, in 2–3 Absätze gegliedert. – Lesbar, aber nicht allzu stark ausdifferenziert. – Quellen vorhanden, aber teilweise wiederholt (zdf.de) | Gesamtnote: BEFRIEDIGEND. Begründung: Die Antwort liefert klare und korrekte Hauptgründe für die Vertrauensfrage (Bruch der Koalition, Minderheitsregierung und Neuwahlen). Detailtiefe könnte erhöht werden, Struktur ist einfach, aber gut verständlich. Quellen vorhanden, aber teilweise wiederholt (zdf.de). |
Legende zur Notenskala
- SEHR GUT: Sehr umfangreiche, korrekte und gut belegte Darstellung
- GUT: Solide und angemessen ausführliche Erklärung mit nur kleinen Lücken
- BEFRIEDIGEND: Kernaussage korrekt, aber Kontext teilweise lückenhaft oder unscharf
- AUSREICHEND: Nur grobes Grundverständnis, viele Details fehlen
- MANGELHAFT: Erfüllt die Fragestellung kaum, stark ungenügende Informationen
Ergebnisse des Vergleichs in Stichpunkten
- Phind und Deepseek sind die besten Anbieter für tiefgehende Recherchen
- Le Chat, Claude bei you.com, Perplexity AI, Kagi und GPT-4o liefern solide Ergebnisse, bleiben im Detail aber etwas oberflächlicher
- Google Gemini versagte im Test, aus der Angst eine falsche Antwort zu geben
- Für einfache Fragen sind die meisten LLM-Suchmaschinen geeignet
- Bei komplexen Themen lohnt sich der Griff zu spezialisierten Anbietern wie Phind
- Quelltransparenz und Detailtiefe sind wichtige Qualitätskriterien
- LLM-Suchmaschinen haben großes Potenzial, müssen sich aber noch weiterentwickeln
Insgesamt zeigt der Test, dass LLM-basierte Suchmaschinen eine vielversprechende Ergänzung zu klassischen Systemen wie Google sein können. Gerade für komplexere Themen liefern sie oft bessere Ergebnisse.
Allerdings gibt es noch deutliche Qualitätsunterschiede zwischen den Anbietern. Phind und Deepseek stechen positiv hervor, während Google Gemini enttäuscht. Für die Zukunft bleibt spannend, wie sich dieser Markt weiterentwickeln wird. Das Potenzial ist auf jeden Fall enorm.


{kind=link}
This AI search engine comparison is so helpful! It clearly explains the pros, cons and use cases of different tools. Whether for daily searches or professional research, you can pick the right tool accurately—saves lots of trial time, definitely saved!